【BigData Key Skills】: Part 3. Add New Columns and Conditional Processing

In previous two sections, we talked about how to sort, dedup and subset data. In this section, we are going to discuss on another important skill in data analysis: how to add new columns to an existing data? In R, this operation is called data mutation.
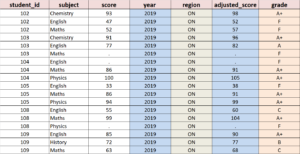
For example, given the below input data called Score, we want to add 4 new columns year, region, adjusted_score, grade to it. The year and region columns have constant values across all the rows. Furthermore, we often need to add new columns by performing calculations based on some conditions. For example, the adjusted_score column is calculated using score column, while the grade column is created based on the adjusted_score. This kind of data operation is called conditional execution or processing, which is an important and mandatory skill required for data work. We will show how to fulfill these tasks in SAS, SQL, R and Python as follows.
SAS
It is very easy and simple to add new columns in SAS programming. As illustrated below, we can perform the conditional processing easily by using IF…ELSE and CASE…WHEN approaches.
**************** SAS Method. **********************;
data mutate;
set score;
year=2019;
region='ON';
adjusted_score=score + 5;
if adjusted_score>=90 then grade="A+";
else if adjusted_score>=80 then grade="A";
else if adjusted_score>=70 then grade="B";
else if adjusted_score>=60 then grade="C";
else grade="F";
run;
************* Proc SQL method. ***********************;
proc sql;
create table mutate as
select *,
2019 as year,
'ON' as region,
score + 5 as adjusted_score,
case when calculated Adjusted_Score >=90 then 'A+'
when calculated Adjusted_Score >=80 then 'A'
when calculated Adjusted_Score >=70 then 'B'
when calculated Adjusted_Score >=60 then 'C'
else 'F' end as Grade
from score;
quit;Code language: SAS (sas)Please note: the CALCULATED keyword in Proc SQL is a very useful and unique option in SAS, which allows us to use the newly created variable from current query immediately. Unfortunately, native SQL languages do NOT have this option. As a result, we have to use an additional sub-query in some cases, which is really inconvenient and annoying.
R
In R programming, the most convenient way to add multiple columns is to use the mutate() and case_when() functions in dplyr package. Actually, the case_when() function was derived from SQL language and it is the equivalent counterpart in R.
mutate<- score %>%
mutate(year=2019,
region='ON,
adjusted_score=score+5,
grade=case_when(adjusted_score>=90 ~ 'A+',
adjusted_score>=80 ~ 'A',
adjusted_score>=70 ~ 'B',
adjusted_score>=60 ~ 'C',
TRUE~'F' ) Code language: R (r)Python
Similarly, Python has the assign() function which is equivalent to the mutate() function in R. Below syntax demonstrates how to perform the same jobs in Python. When performing conditional execution in Python, we need to define a custom function first, then apply it to the interested variable.
#### Define custom function for conditional processing ###
def grade(x):
if pd.isnull(x):
return 'N/A'
elif x>=90 :
return 'A+'
elif x>=85:
return 'A'
elif x>=80:
return 'B'
elif x>=70:
return 'C'
elif x>=60:
return 'D'
else:
return 'F'
mutate=score.assign(year=2019,
region='ON',
adjusted_score=score['score'] + 5 )
mutate=mutate['adjusted_score'].apply(grade) Code language: Python (python)SQL
In native SQL languages such as Oracle, DB2, Teradate etc., or the SQL-like languages such as Hive, Spark etc., they all provide the similar CASE…WHEN clause to perform conditional processing. Native SQL languages do NOT have the CALCULATED option in SAS, therefore we cannot use a variable newly created in the current query. Under some circumstances, we must use an additional sub-query to do it, which is very inconvenient.
create table schema.mutate as
select *,
2019 as year,
'ON' as region,
score + 5 as adjusted_score,
case when score + 5 >=90 then 'A+'
when score + 5 >=80 then 'A'
when score + 5 >=70 then 'B'
when score + 5 >=60 then 'C'
else 'F' end as grade
from schema.score;Code language: SQL (Structured Query Language) (sql)Summary
Adding new columns and conditional processing are the essential and important skills in manipulating and analyzing big data. We hereby exemplified how to perform them in different languages such as SAS, R, Python and SQL. It can help you to learn and utilize them quickly.
Outreach
Nowadays, big data analytics is prevailing in numerous industries and fields. SAS, SQL, R and Python are the most widely used analytic tools for data scientists and analysts. The question is: how can you learn and grasp them quickly?
As we have demonstrated so far, a quick and efficient way of learning them is to understand and compare them with one another. All analytic tools perform the same data manipulations in real work, though they have different syntax in programming. Compare and connect them with the essential tasks in real work, this is the best learning strategy without any doubt. Below is a whole picture of the key data skills required for business analysts and data scientists in daily work:
- Read in data from various sources
- Data validation and verification
- Sort and dedup data
- Subset data vertically and horizontally
- Expand data vertically and horizontally
- Add new columns and conditional processing
- Summarize and aggregate data
- Reshape data: transpose and rotate
- Create tables, graphs and plots
- Write out data to external files
Interested and want to learn more? Please join the training program by Dr. Justin Jia, you can learn and master these key skills in SAS/SQL/R/Python very quickly.
Teaching is an art, learning is too!
Cool read!
Great experience ! Thanks for sharing!
Welcome!
Useful.
Thanks, any questions?