一道面试题引发的 “大案”
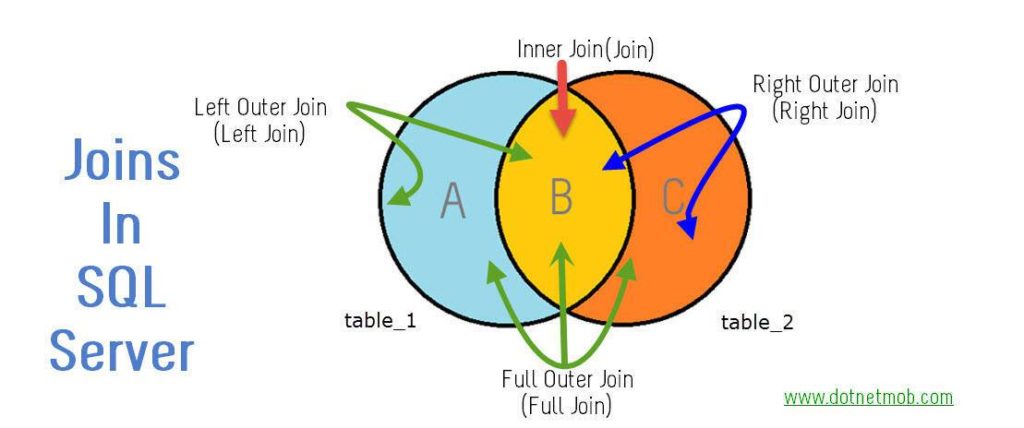
昨天一个学生去一个金融公司面试,面试官问了一个 SQL join 问题:Suppose we have 2 tables, they both have some duplicates on the ID variable ( the linking key). If we full join them together, what is the range of the records in the output table?
我想把这个问题更深入一下,附加一个问题:If we link them together by SAS DATA step MERGE rather than SQL join, what is the range of the records in the output table?
实际上,2011 年我去 Rogers 电信公司面试,他们就问了一个类似的问题。这两个问题看似简单,实际上水很深,涉及到 SAS 和 SQL 处理数据的不同机理。如果不了解这些,根本不可能答对。下面就借此深入说说。
SQL Join:
SQL join 连接数据的机理是 Cartesian Product. 简而言之,就是先上来不管三七二十一,先产生一个: an intermediate Cartesian product by cross-combination of all the records in both tables, then subset it based on the specified joining keys and Inner/Left/Right/Full conditions. Let’s use below sample data to illustrate the mechanism.
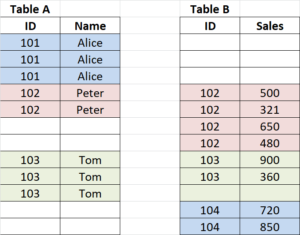
If we use below code to full join them together, here is the joining process:
create table C as
select a.*,
b.ID as ID2,
b.Sales
from A a full join B b
on a.ID=b.ID;Code language: SQL (Structured Query Language) (sql)Step 1: Create a cross-combination Cartesian product, we will have 8 X 8= 64 records.
Step 2: Subset the above Cartesian product based on the joining key ID and the Inner/Left/Right/Full Join condition.
For the common part (inner join part), where the records having ID present in both tables, SQL subsets it based on the “a.ID=b.ID” condition, therefore we get:
ID=102: 2 X 4= 8 records
ID=103: 3 X 2= 6 records
The non-matching outer part:
Left part, ID=101: 3 records
Right part, ID=104: 2 records
So the total number of output records is:
Inner join: 2 X 4 + 3 X 2 = 14
Left: 3 + 2 X 4 + 3 X 2 = 17
Right join: 2 X 4 + 3 X 2 + 2= 16
Full join: 3 + 2 X 4 + 3 X 2 + 2= 19
如果理解了这个 SQL Join 的机理,我们可以接下来推算一下普遍情况。假设:
Table A: total records=a, some IDs exist in both tables, and the number of records are c1, c2, c3…. ck respectively.
Table B: total records=b, some IDs exist in both tables, and their numbers are d1, d2, d3…. dk respectively.
Then the general formula of total output records is:
T= a- ∑{c(i)} + ∑ { c(i)*d(i)} + b – ∑{d(i)} = a + b + ∑ { c(i)*d(i)} – ∑{c(i)} – ∑{d(i)}
The minimum output: T(min)= a + b, when the 2 tables have no common IDs. The 2 tables are totally independent of each other without any overlap.
The maximum output: T(max)= a*b, when the 2 tables are totally overlapped and with only one unique ID. Therefore, the total number of output records is always between a+b and a*b.
SAS DATA Step Merge:
Unlike the Cartesian product in SQL joins, SAS DATA step MERGE has totally different mechanism to link data together because SAS data step is an iterative process. In each iteration, it only processes one single record. Below shows the result of Table C. Please pay attention to the inner join part. The output table C has 12 records totally, how come? It is because: the inner common part will have records of max{c(i), d(i)} due to the iterative nature of SAS DATA step, rather than {c(i) * d(i)} for SQL joins based on a Cartesian product.
proc sort data=A; by ID; run;
proc sort data=B; by ID; run;
data C;
merge A B;
by ID;
run;Code language: SAS (sas)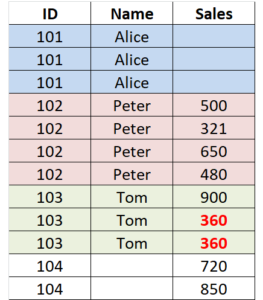
Base on the same assumptions above, the general formula of total output records is:
T= a- ∑{c(i)} + ∑ { max( c(i), d(i) } + b – ∑{d(i)} = a + b + ∑ { max( c(i), d(i) } – ∑{c(i)} – ∑{d(i)}
The minimum output: T(min)= max(a, b), when the 2 tables are totally overlapped and with only one unique ID.
The maximum output: T(max)= a + b, when the 2 tables have no common IDs. The 2 tables are totally independent of each other without any overlap.
Therefore, the total number of output records is always between max(a, b) and a+b. However, the extreme values occur under circumstances that are totally opposite to the SQL join. Interesting and incredible? Test it in SAS!
Please note: Because of this feature in SAS merge, therefore, we CANNOT use it to link data when it is a Many to Many merge, namely data has duplicates in both tables. It will mess up your data. In this case, we can only use SQL join to match them together if a Cartesian product is desired. In real work, we must check duplicates in data before we join or merge them together!!!
For Python, the merge() function in pandas library uses the same mechanism as the SQL join. So, you can work out the answer for Python easily too.
SQL 是大数据分析最基本的技能,因为所有的数据都来自大型数据库,使用 SQL 来 query and manipulate data 是必需的第一步。而 join 数据是最重要的工作之一,所以这也是面试最常问的问题!Get prepared for it, 机会只给有准备的人噢!
kraken15.at
[url=https://krraken15at.com]KRAKEN15.AT[/url]
KRAKEN15.AT ЗЕРКАЛО
KRAKEN TOR
БЛЕКСПРУТ ЗЕРКАЛО
[url=https://krraken15at.com] KRAKEN15.AT
kraken15.at
[url=https://krraken15at.com]РАБОЧАЯ ССЫЛКА KRAKEN15.AT[/url]
KRAKEN15.AT ЗЕРКАЛО
KRAKEN TOR
БЛЕКСПРУТ ЗЕРКАЛО
[url=https://krraken15at.com] KRAKEN15.AT
bs2best.at
[url=https://bs-2best.com]BS2BEST.AT[/url]
bs2best.at BLACKSPRUT
Устали? Почитайте прикольные анекдоты про евреев
Как появились смешные картинки в сети интернет
Как появились забавные мемы в сети интернет
Как появились прикольные мемы в сети интернет
Как стали популярными забавные мемы в сети интернет
Как стали популярными смешные мемы в сети интернет
Как поднять настроение друзьям
Как улучшить настроение друзьям
Как поднять настроение другу
Как улучшить настроение другу
[url=https://winouii.com]Winoui[/url] se distingue par son incroyable variГ©tГ© de jeux. Avec des centaines de machines Г sous, des options de jeux de table classiques comme le blackjack et la roulette, et une offre complГЁte de casino en direct, il y a toujours quelque chose de nouveau Г explorer. Les nouveautГ©s sont rГ©guliГЁrement ajoutГ©es pour garder l’offre fraГ®che et excitante.
Website: [url=https://winouii.com]www.winouii.com[/url]
La sГ©curitГ© est une prioritГ© absolue chez [url=https://winouii.com]Winoui[/url]. Nous utilisons les technologies de cryptage les plus avancГ©es pour garantir que toutes vos transactions et donnГ©es personnelles sont protГ©gГ©es. De plus, nous offrons une variГ©tГ© d’options de paiement pour faciliter vos dГ©pГґts et retraits de maniГЁre rapide et sГ©curisГ©e.
Website: [url=https://winouii.com]https://winouii.com[/url]
[url=https://winouii.com]Winoui[/url] offre une expГ©rience de jeu en ligne inoubliable avec sa vaste gamme de jeux de haute qualitГ©. Que vous soyez un amateur de machines Г sous, de jeux de table, ou de casino en direct, Winoui a quelque chose Г offrir Г chaque type de joueur. Rejoignez-nous pour dГ©couvrir une plateforme sГ»re et divertissante!
Website: https://winouii.com
Арматурный прокат служит основой для укрепления железобетонных конструкций в строительстве. Это значительно увеличивает прочность и долговечность зданий, мостов и других сооружений, способных выдерживать значительные нагрузки.
[url=https://telegra.ph/Sfery-primeneniya-stalnoj-armatury-v-zavisimosti-ot-diametra-prutka—gde-ispolzuyut-tonkuyu-srednyuyu-ili-tolstuyu-armaturu-10-14]Стальная строительная арматура в Москве.[/url]
Класс А240 — это арматура, используемая в конструкциях с небольшими нагрузками. Её диаметр обычно не превышает 10 мм, и она часто применяется для формирования каркасов в малоэтажном строительстве.
http://armatura-12.ru
труба профильная купить
Заказать Хавал – только у нас вы найдете разные комплектации. Быстрей всего сделать заказ на haval jolion комплектации и цены уфа можно только у нас!
[url=https://jolion-ufa1.ru]купить haval jolion[/url]
хавал джолион комплектации и цены уфа – [url=https://www.jolion-ufa1.ru]http://www.jolion-ufa1.ru[/url]
Заказать Haval – только у нас вы найдете цены ниже рынка. Быстрей всего сделать заказ на новый хавал джолион можно только у нас!
[url=https://jolion-ufa1.ru]купить хавал джолион в уфе цена[/url]
хавейл джолион цена и комплектация – [url=https://jolion-ufa1.ru/]https://www.jolion-ufa1.ru[/url]
Create AI-Generated Coloring Books Pages
[url=https://www.painty.cc/]Coloring Page[/url]
AI can generate stunning artwork in seconds. Try it yourself at [url=https://telegra.ph/The-Tragic-Beauty-of-Vampire-Love-in-Gothic-Design-03-23]this website here[/url].
Okay, reader, I literally just ran into something insanely awesome, I had to shut my tabs and scream about it.
This piece is totally bonkers. It’s packed with smooth UX, creative magic, and just the right amount of designer madness.
Suspicious yet? Alright, [url=http://iwanttomeetyou.net/__media__/js/netsoltrademark.php?d=snargl.com%2Fblog%2Fradagast-parable-a-journey-through-nature-and-craftsmanship%2F]witness the madness right below[/url]!
Didn’t click? Fine. Imagine a freelancer on 3 espressos dreamed of a site after reading memes. That’s the vibe this thing of wonder gives.
So hit it, and bookmark it forever. Because honestly, this is pure genius.
That’s it.
Jupiter’s quote API powers many Solana wallets. Have you noticed how consistent the pricing is?
jupiter exchange
Jupiter’s quote API powers many Solana wallets. Have you noticed how consistent the pricing is?
jupiter Exchange USA
проститутки стерлитамак тг проститутки индивидуалки стерлитамак