【BigData Key Skills】: Part 1. Sort and Dedup Data

Currently, big data analytics are widely used in many industries such as financial, telecom, insurance and retail industries. As it is well known, the most popular analytic tools are SAS, R, Python and SQL. SAS/R/Python are independent data tools developed for scientific calculations or data processing. Python is a general programming language, it is not only for processing data. However, Python is powerful in leveraging and analyzing big data too via the use of pandas and numpy packages.
SQL stands for Structured Query Language, it is a data query tool built in with all relational databases such as Oracle, DB2, Teradata, SQL Server etc. For any data analysis work, the first step is to access and extract data from corporate databases, so SQL is definitely an essential and mandatory skill for big data analysis.
Therefore, SAS/R/Python/SQL are the 4 important skills for data analysts and scientists. Grasping them can enable you to work in most industries and analytic fields. Actually, all the analytic tools and data processing languages are similar. A good and efficient way to learn them is to compare one with another and connect the essential skills together. In this way, you can learn and master them very quickly. Therefore, in this writing series, I will not only introduce the fundamental skills for big data analysis such as sort/dedup, subset/expand, aggregate/break down, reshape data etc, I also illustrate them with SAS/R/Python and SQL syntax. If you can understand and practice them, you are able to grasp all the 4 analytic tools rapidly.
In this section, we use below Score example data for the illustrations, which is a student score data with 3 columns and 18 observations.
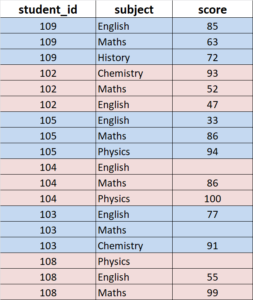
Please note: SAS and SQL syntax is NOT case sensitive, it does not matter if you use lower or upper cases in coding. However, R and Python are case sensitive languages, letter cases do matter!
SAS
It is very simple to sort and dedup data in SAS by using Proc Sort procedure. As shown below, SAS syntax is very straightforward and easy to understand. By default, variables are sorted in ascending order, however, you can use DESCENDING option to change it. You can also sort data by multiple variables as shown below. If you want to remove duplicates from data, just use NODUPKEY option, it will dedup data to the desired level. Below table shows the output data after dedup by student_id.
proc sort data=Score out=sorted ;
by student_id;
/*by descending student_id; */
/*by subject descending score; */
run;
proc sort data=Score out=deduped nodupkey;
by student_id ;
/* by subject student_id; */
run;Code language: SAS (sas)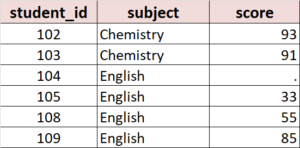
R
R is an open source language with many libraries and packages. For data manipulation, dplyr library is the most powerful package and it is used by all data scientists and analysts. So we will focus our examples on this package only. Please note: you need to install and import the dplyr into R first before you use it.
As illustrated below, we can use the arrange() function in R to sort data. The default order is ascending, we can use the desc option to order it in descending. To remove duplicates, we can utilize the distinct() function. The .keep_all=FALSE/TRUE option is used to choose the output variables. For example, if you dedup data by student_id and set it to FALSE, the output will only have the student_id column. The output will keep other variables if it is set to TRUE, which produces the same result as above SAS output . In general, FALSE will only retain the sorting variables, while TRUE keep all input variables.
library(dplyr) ### import dplyr package into R.
### sort data
sorted<- score %>% arrange(student_id)
sorted<- score %>% arrange(subject, desc(score) )
### dedup data
deduped<- score %>% distinct(student_id, .keep_all =TRUE)
deduped<- score %>% distinct(subject, student_id, .keep_all =TRUE)
Code language: R (r)Python
Python provides the pandas library to manipulate data, pandas offers the sort_values() and drop_duplicates() functions to sort and dedup data respectively. Similarly, we use the ascending=True/FALSE option to control the sorting order. If you use multiple sort variables, you need to use a list to specify them as demonstrated below.
If data contains duplicates, we can apply the keep=’first’/’last’/’false’ option to choose which record to retain. The default option is ‘first’, which will keep the first one of duplicated records. ‘last’ will keep the last one, and ‘false’ option will remove all of them.
### sort data
sorted=score.sort_values(['student_id'])
sorted=score.sort_values(['subject', 'score], ascending=[True, False])
###dedup data
deduped=score.drop_duplicates(['student_id'], keep='first')
deduped=score.drop_duplicates(['subject', 'student_id'], keep='last')
Code language: Python (python)SQL
In SQL, we sort data by using ORDER BY clause, and using the desc option to do it in descending order. Below code illustrates their uses. However, it is tricky to dedup data with SQL. Many beginners tend to use SELECT DISTINCT to remove duplicates, however, this is actually WRONG! When you use “Select distinct student_id, subject, score”, it means that you select all the unique combinations of all the 3 variables rather than unique student_id only. Given our data, it will NOT remove duplicates at all. The correct way is to use a sub-query along with the row_number() over() window function. This function will assign a unique sequence number for each record of same student_id, then we can use the WHERE clause to dedup data. You can learn more about window functions using the references if interested.
In 2019 summer, a student got a job interview test with TD insurance. One question was about how to dedup data in SQL. He used the wrong method at beginning but I corrected it with the right one. Finally, he got the job offer from TD Insurance.
create table Sorted as
select *
from Score
order by student_id;
create table Sorted as
select *
from Score
order by subject desc, score;
##### Wrong way to dedup data !!! ##############
create table Deduped as
select distinct student_id, subject, score
from Score;
##### Correct way to dedup data !!! ##############
create table Deduped as
select b.*
from
(select *,
row_number() over (partition by student_id order by subject) as dedup_index
from Score a ) b
where b.dedup_index=1 ;Code language: SQL (Structured Query Language) (sql)Summary
Sort and dedup data are the essential and important skills in manipulating and analyzing big data, though they seems to be simple. An in-depth understanding of them will enable you to use them appropriately and error-free.
A very helpful article!
Btw, I have some sas training credit to use, any recommendations? How about courses on dada science? Thanks!